RNN, Attention, Transformer, BERT简介
RNN(Recurrence Neural Network)
背景
有时候我们需要根据历史信息来判断未来的趋势。例如,给一句话,挖掉最后一个单词,让机器预测这个单词最大概率是什么。那机器不能只依据这个序列的最后一个单词(指挖掉的单词前面的那个单词)来判断最后一个单词填什么,而应该根据整个序列由前到后地推断。
“Sequence modeling”
实现
为了记住历史信息,引入了RNN。
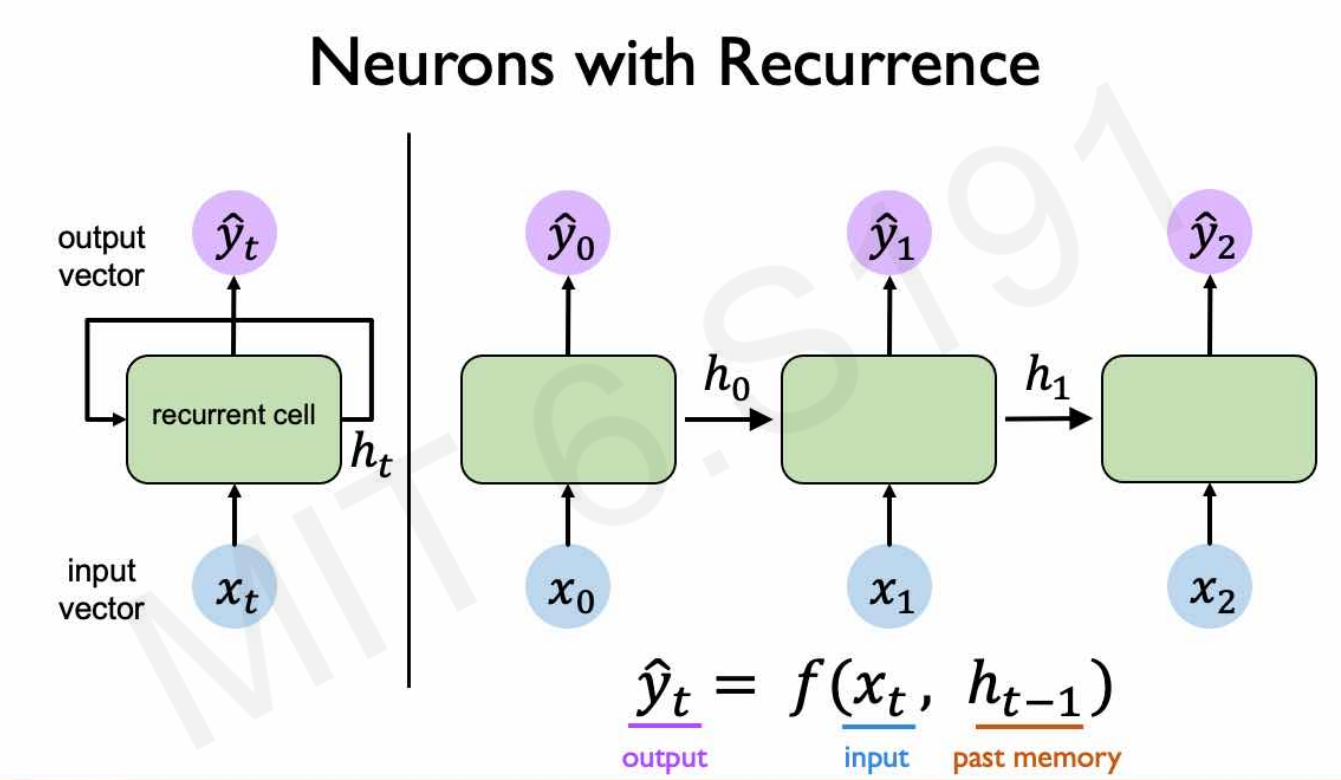
假设激活函数是tanh,RNN的计算公式(为了写起来简单就不加粗了,但是都是向量、矩阵):
\[h_t = \tanh(W_xx_t+W_hh_{t-1})\\ \hat{y}_t = W_oh_t\]在$h_t$的计算中引入了历史信息$h_{t-1}$。
Attention
RNN的不足
- 没有长期记忆。t时刻的执行与t-1时刻关系最紧密,与更早时刻关联比较弱,与t+1之后的执行没有关联。但是,考虑这一句话:“Bark is very cute and he is a dog”,“he”与“Bark”“dog”的关系最紧密,与它前面的单词“and”关系反而不大。
- 难以并行化。后一步执行必须等待当前步执行完毕,才能计算。
- 存在梯度消失和梯度爆炸。尤其到t很大的时候,从$h_t$反向传播到$h_0$,会出现多个相同数连乘的情况,很容易趋于0或趋于无穷。
例子:数据库查询
数据库按照键值对的方式组织,也就是一个键(key)对应一个值(value)。查询时,用户给出请求(query),query到数据库中,与所有的key逐个比对。若发现某个key与query最接近,就把这个key对应的value返回,这就完成了一次查找。
Attention基本原理与这个接近,可以把一个单词看作一个query,一句话就是一个数据库。这句话中,与query关系越紧密的单词,它的权重就越高。
Self-Attention就是拿一句话中的每个单词与这一句话的全部单词进行比对,同样,关系越相近的单词权重就越高。例如,给出一句话“He tossed this tennis ball to serve”,下图就是其Self-Attention的示意:
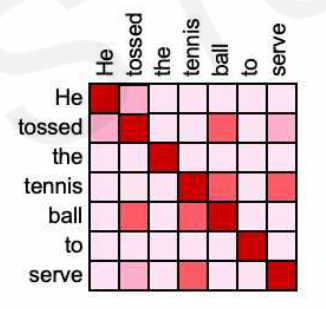
为什么叫Attention?因为关系越相近的单词,我们的“关注度”(即赋予它的权重)越高。
实现
(1) 输入一句话,对每个单词,都给出其embedding向量$V_i$。这句话就变成了一个向量组$[V_1, V_2, …, V_n]$。
所有单词都在同一个embedding space中,每个单词都是这个embedding space中的一个向量。embedding space按照单词语义远近组织,语义相近的单词在embedding space中也相近。
(2) 单词在语句中有顺序(顺序很重要!),因此再对每个单词给出其位置embedding向量$P_i$,记为$[P_1, P_2, …, P_n]$。
(3) 将$V_i$和$P_i$相加,为了便于表述,再记为$V_i$。这就是包含了单词词义和顺序信息的最终输入向量组。
(4) 引入$M_k$矩阵,它表示key信息。做矩阵乘法$[V_1, V_2, …, V_n]M_k$,这样每个向量就都附上了key。
(5) 引入$M_q$矩阵,它表示query信息。做矩阵乘法$[V_1, V_2, …, V_n]M_q=Q$。
(6) 计算Attention权重。计算矩阵乘法$QK^T=W$即可,只要query与key足够接近,乘积矩阵中对应元素的值就越大,也就是权重越高。
(7) 经过一个softmax层,对W矩阵做归一化操作。
(8) 引入$M_v$矩阵,它表示value信息。做矩阵乘法$[V_1, V_2, …, V_n]M_v = [V’_1, V’_2, …, V’_n]$。
(9) 计算Attention值:$Attention = \sum_{i=1}^nV’_iW$。容易发现,Attention和输入向量V有相同的维度。
Attention如何克服RNN的不足?
- 任意两个单词都能找到联系,这就有了长期记忆。
- 存在大量矩阵计算,很容易实现并行化。
- 反向传播(BP)阶段,由于不是按照时间序一步一步计算的,因此不存在连乘状况,自然没有梯度消失和梯度爆炸。
Multi-Head Attention
只使用一组$M_k, M_q, M_v$矩阵,效率比较低,且发现的联系也比较少。因此引入多组参数矩阵,称每组为一个“head”,将所有head计算出的Attention值拼接起来,形成最终的Attention值,这就是Multi-Head Attention。
Transformer
Transformer是使用self-attention机制加速机器翻译的一个模型,于2017年提出。
Transformer结构如下:
其中,encoder和decoder的结构如下:
|———————————————————| |———————————————————|
| | | |
| | | |
| | | Feed Forward |
| Feed Forward | | ↑ |
| ↑ | | | |
| | | | Attention |
| Self Attention | | ↑ |
| | | | |
| | | Self Attention |
| | | |
| | | |
|———————————————————| |———————————————————|
encoder decoder
encoder中使用了Self Attention机制,更准确地说是Multi-Head Self Attention,前面已经介绍过。Self Attention计算结果再经过一个前馈神经网络,然后传递给下一个encoder。
decoder与encoder的结构类似,不同的是,在经过第一次Self Attention的计算之后,还要与之前的encoder输出结果做一次Attention,然后再送入前馈神经网络。
具体技术细节和训练过程可以参考这篇文章:https://zhuanlan.zhihu.com/p/166608727。
BERT
BERT是基于Transformer的自然语言理解(NLP)模型。简单理解就是,BERT会基于输入文本,生成与上下文相关的embedding,既有单词的embedding,又有句子的embedding。
如何训练BERT
BERT是一种预训练模型,它的预训练目标就是生成一个好用的NLP模型,因此只用到了Transformer中的encoder。BERT的训练方式主要有两种:
(1) MLM(Masked Language Modeling)。简单地说,BERT会接收一个文本序列,但是序列中有15%的单词被[MASK] token所代替。它的训练目标就是预测出[MASK]之下的单词。
(2) NSP(Next Sentence Prediction)。简单地说,BERT会接收到许多“句子对”,BERT需要判断出每组“句子对”中第二句话是否是第一句话之后应该说的话。这些句子对中有50%有承接关系,另外50%两句话没有关系。
在NSP中,输入文本的第一句话前面会加上一个[CLS]token,每句话的最后会加上一个[SEP]token用以标记。最后[CLS]的输出会被转换成一个2×1的向量,然后送入一个分类层,来确定第二句话是否是第一句话的后继。
如何运用BERT
BERT可以用于多种NLP任务,只需要在核心模型之后加上一个layer即可。例如:
(1) 分类任务(例如某个影评是积极的还是消极的)。这种任务和NSP比较像,只需要在[CLS] token的输出后面加上一个分类层即可。
(2) 问答任务。这类任务会针对一个文本做出提问,机器需要根据问题,将正确答案在文本中标记出来。使用BERT来完成这类任务时,可以另外训练两个向量,用于标记文本中正确答案的开始位置和结束位置。
(3) 命名实体识别(NER)任务。这类任务会将一个文本序列输入机器,机器需要标记出文本中的不同命名实体(比如XXX是人物/地点/组织……)。使用BERT来完成这类任务时,只需要把每个token的输出向量放进一个分类层即可。
有个YouTube视频大致演示了如何在python中调用BERT,完成一些简单的任务:
参考资料: